
Visual attention
CNN + LSTM (VGG-16 or ResNet)
- VGG-16에서 CNN의 여러 Convolution과 Max Pooling을 거치고 나면, 결국 Feature Extraction을 하게 될 수 있을 정도의 size가 된다.
- 이때 One dimensional vector로 바꾼 후에 Fully connected layer를 거치게 된 후, 분류를 할 때는 Softmax function 이후 classification을 하게 된다.
- Image Captioning을 하는 경우 softmax를 하지 않고 바로 Feature Extraction된 벡터를 LSTM에 투입한다.
- LSTM의 input으로 들어갈 때
- 처음 Input이 계속 동일한 input으로 들어가게 되는 경우
- 초기 input vector를 , 번째의 hidden node를 라 하면
- output을 다음 hidden cell의 input으로 들어가지 않음
- 나중의 output이 다시 새로운 input으로 들어가는 경우
- 번째의 hidden node를 , output을 , input을 라 하면
- output이 다음 hidden cell의 input으로 들어감
- 처음 Input이 계속 동일한 input으로 들어가게 되는 경우
- 이후 output에서 softmax를 거친 이후 output을 뽑아냄
Visual attention
- 하지만 1번과 2번 모두 단점이 뚜렷하게 있는데, 모두 size의 문제라고 생각하기 편하다.
- 1번 같은 경우 input vector가 계속 반복해서 들어가기 때문에, 의 크기가 작지는 않은 이유로 학습이 쉽지만은 않다. (의 크기가 작으면 정보 손실이 일어날 수 있음)
- 동일하게 2번 같은 경우 의 크기는 적당할 수 있으나, 의 크기가 굉장히 클 수 밖에 없고, 1번과 동일한 이유로 학습이 쉽지 않음
- 또한, parameter들의 역할을 할 수 없으므로 해당 paramaeter가 어디에 어느 정도로 영향을 주는지 알 수 없는 문제점이 있음
- 이를 해결하기 위해 이전의 결과와 초기 상태를 참고하여 현재의 결과를 도출하는 방안이 고안되었고, 이가 attention이다.
- 한글로 해석하면 주목하다라는 뜻을 가지는 attention은 말 그대로 현재 이 model이 어디에 주목하여 결과를 내야 하는지 알려주는 일종의 보조 도구이다.
- 추후 Seq2Seq에 대해 소개하겠지만, 현재 image에서 처리하는 경우 “어디”라는 정보는 굉장히 다루기 쉽지 않다.
- Convolution을 하고 feature extraction을 하는 과정에서 spitial한 information은 사라지므로, 그 이전의 결과를 끄집어낼 필요가 있다. ⇒ 따라서 중간 과정에서 어느 정도 spitial한 정보가 살아있으면서, feature도 괜찮게 정리되어 있는 부분을 기준으로 attention을 진행한다.
- But How?
- spitial한 information을 활용하기 위해 공간을 N등분하여 각각에 대해 convolution 과정을 거친 후, 각각에 대해 feature extraction을 하여 이것들에 대해 input이 들어간다.
- 이전에는 식이 에서 가 등분 없이 진행한 vector였다면, 으로 하여 이전의 state인 에 대해 weighted sum을 하고, 이 수치를 이용하여 결정, 즉 식이 이 된다.
- 이제 attention 함수에 대해 알아보자.
Attention function
- 앞에서도 말했다시피 각각의 등분한 vector과 이전의 상태 을 이용하여 현재 어디에 주목해야하는지를 찾아야 한다.
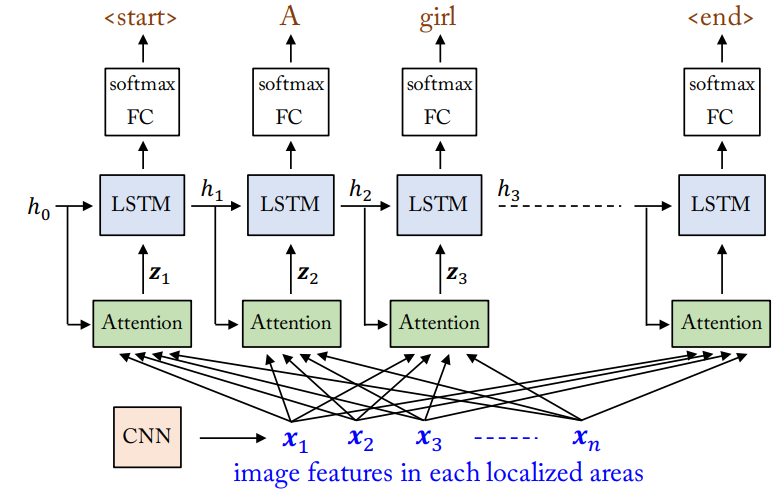
- 먼저 N등분한 image feature에서 각각의 attention으로 fullay connected layer를 하나 만들고, 과거의 정보를 들고와서 attention을 한다.
- 이때 “내가 이 정보를 얼마나 볼 것인가?”에 대해 에 대한 weighted sum으로 나타내는데, 단순히 값만 사용하게 되면 값이 너무 커지거나 작아지는 등 점차 의미가 없어진다.
- 즉, weight의 decay를 방지하기 위해 normalization을 하는 과정이 필요하고, 이때 가장 좋은 것은 softmax
- 따라서 번째의 attention result(정식 명칭이 있는데 까먹었습니다..) 는 으로 적을 수 있다. 이때
- 이고, 가장 대표적으로 를 활용한 이 있다. (와 은 learnable한 matrix, 뒤의 attention을 Bahdanau attention이라 함)
Seq2Seq attention
- 기계번역 같은 경우 문장을 받아들이는 Encoder 부분과 그 문장을 받아 번역된 결과를 출력하는 decoder 부분으로 나누어져있다.
- Visual attention에서의 내용과 동일하게, 문장의 단어들을 거쳐가면서 여러 feature들이 담기게 되는데, 그렇게 되면 마지막의 feature vector에는 모든 cell의 feature들을 담아놓아야함 ⇒ feature vector가 굉장히 커야 정보 손실이 적어짐 ⇒ 굉장히 손해
- 결국, 이전의 node들에 대한 정보를 출력할 때마다 참고할 필요가 있고, 이는 attention으로 다소 해결할 수 있음
- 결국, 이전의 node들에 대한 정보를 출력할 때마다 참고할 필요가 있고, 이는 attention으로 다소 해결할 수 있음
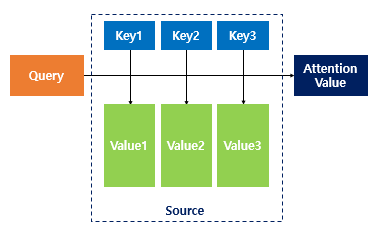
- Seq2Seq에서는 “이 상황”에서는 “어느 값” 때문에 “어떤 값”을 최대화 해야하는지에 대한 정보가 필요하고, 이를 차례대로 Query, Key, Value라고 한다.
- 즉, 질의를 던져서(Query) Key들 중 가장 연관이 높은 것을 찾아서 Key와 mapping되는 value를 찾아서 곱하고, 이를 바탕으로 계산을 하는 것이다.
- Attention을 가장 잘 활용한 Model인 Transformer에서는 Self-attention을 활용하고, 이 모델을 기점으로 Self-attention이 굉장히 대중화 되었다.

[출처] : https://wikidocs.net/22893
- 암튼, 식을 알아보면, 번째 때의 encoder hidden node를 , decoder hidden node를 라 하자. 현재 상황을 기준으로 질문을 던져야 하므로 query는 , 어느 단어가 적절한 지 확인해야하므로 Key는 , 그 Key의 단어를 많이 반영해야하므로 Value도 이다.
- 즉, 번째 (Non-softmax)attention weight (번째 때 번째 encoder node에 대한 attention weight)은 (Dot product) 또는 (General attention) 또는 (는 concat operation)
- 이후 attention weight들에 대해 전체적으로 softmax를 취하면 attention weight들이 완성이 되고, 이것들과 Value인 를 다시 dot product를 하면 context vector를 계산할 수 있다.
- 마지막으로 attention value 와 previous hidden state 를 concat하고, 상황에 맞게 non-linear한 함수를 취해주면 now state 을 만들 수 있다. 이를 이용하여 output을 만들 수 있음
- (는 번째로 생성해낸 단어, 번째로 번역한 단어의 임베딩 벡터를 이용하는 식을 사용)
- 논문에서는
-
-
-
- , , , , , , , , 은 학습해야하는 Matrix, 은 element-wise multiplication을 의미한다.
- 를 사용
Uploaded by N2T