
Auto Encoder
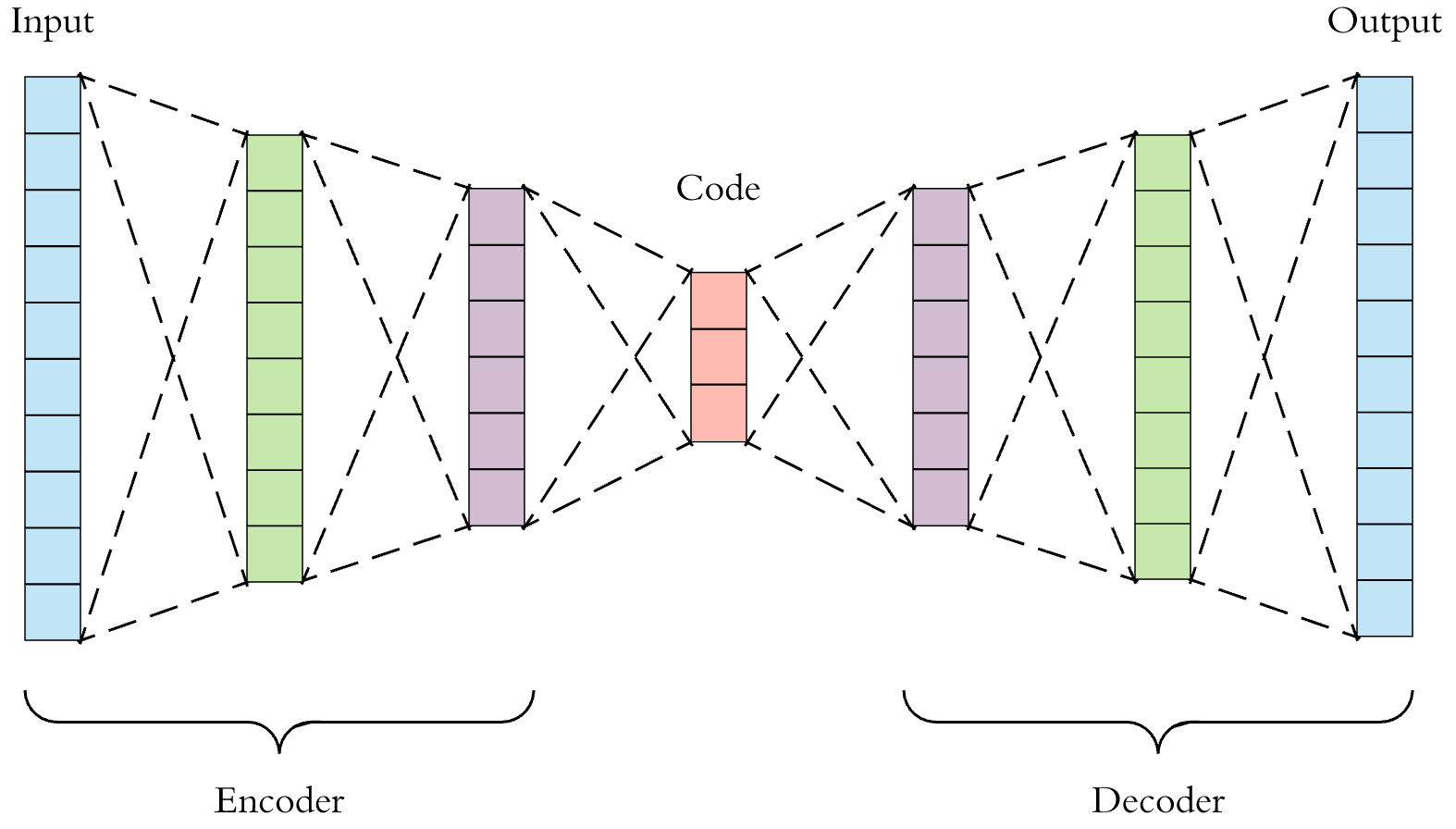
- 이제 주제를 틀어, 어떠한 Input이 들어왔을 때 그걸 더 낮은 dimension으로 어떻게 줄이는지에 대해 알아보자.
- 이가 중요한 이유는, Convolution을 생각해보면 편하다.
- Convolution의 성능은 분류를 얼마나 잘하는가?이고, FC의 특성을 생각하면 결국 이는 최종 Feature vector을 얼마나 잘 나타냈는가?로 요약할 수 있다.
- 즉, 큰 dimension의 vector를 low dimension으로 낮추면서 특징을 잘 가져가는 것은 아주 중요한 문제이다.
- 이렇게 낮은 차원으로 줄인 벡터를 laten vector라고 하는데, 이 laten vector가 잘 나왔는지 아닌지는 direct로 판별할 수는 없다. (결과가 없기 때문)
- 즉, 이 laten vector로 다시 이미지를 만들고, 이 이미지와 원래 이미지가 얼마나 차이나는지로 확인해야 한다. (Transposed convolution)
- Label(result)이 없기 때문에 이전까지의 Supervised Learning이 아닌, Unsupervised learning 에 속하게 된다.
- 이 Encoder-decoder 구성을 Auto Encoder라고 하는데, 3가지 특징이 있다.
- Dimension reduction
- 말했다시피 이미지를 작은 차원으로, 많은 정보를 가지면서 compressing 하는 것이 중요하다.
- 이후 그 벡터를 이용하여 원본을 복구해야한다.
- 압축한 벡터를 laten vector라고 한다.
- Data specific
- Input 같은 경우 특징이 서로 상관관계가 많이 있거나, 서로 비슷한 이미지들이어야 한다.
- Lossy
- Reconstruction 같은 경우 결국은 작은 차원에서 큰 차원으로 복구 하는 것이므로, 완벽하게 복구하는 것은 거의 불가능에 가깝다.
- 따라서 원본에 비해 좋지 않은 화질의 문서가 나오는 것은 당연하다.
- Dimension reduction
Goal of AE
- 번째 input을 , 이에 대한 AE의 output을 라 하면 우리의 목표는 모든 case에 대한 loss를 줄이는 것이 목표다.
- 연속적이지 않는 경우(Binary) Cross-Entropy를 사용하면 되고,그 경우 식은
Dimension reduction
- 앞에서 소개했던 Dimension reduction 같은 경우 자체적으로 차원을 줄인다 말고도, 한 가지 의미가 더 있다.
- 차원을 잘 줄였다는 것은 Feature들을 잘 catch했다는 것이고, 그러면 원본 이미지의 특징을 그래프로 Plot화 할 수 있다는 장점이 있다.
- 특히, 2차원이나 3차원 같은 경우 잘 찍으면 이걸 이용하여 Clustering이 가능하다.
- 앞에서 말한 것은 Data Visualization이라고 하는데, 통계학에서 linear하게 하는 요약하는 방법은 PCA가 있다.
- PCA는 Data들을 linear(Hyperplane, Hyperplane을 보통 로 나타낸다)하게 표현하는 방법이다.
- 그에 반면에 AE는 Data들을 Non-linear한 Manifold로 나타내는 것으로, 곡선의 표현이 가능하기 때문에 보다 정확하게 표현이 가능하다는 장점이 있다.
Practical AE
- 첫번째로는 Tied weight AE인데, Input과 output의 size가 동일하면 Input → laten vector의 행렬을 , laten vector → output의 행렬을 라 하면 로 만들 수 있다.
- 이렇게 Transposed convolution으로 하는 것을 Tied weight라 한다.
- 또한, 이건 반으로 weight들이 줄어들기 때문에 학습이 조금 더 잘된다는 장점이 있다.
- 물론.. 같은 weight를 활용하기 때문에 정확도 자체적으로는 떨어질 수 있다.
- 두번째로는 De-noising AE가 있다.
- 일반적으로 들어오는 input은 항상 clear하지 않고 흐릿하게 noise들이 많이 껴있을 수 있다.
- 그러면 역으로 깨끗한 image에 일부러 noise를 넣어서, 그 noise로 AE를 돌리면 좋지 않은 input들에 대해서도 깨끗한 원본을 얻을 수 있다!
- 이를 Denoising AE라 한다.
- 마지막으로 Stacked AE인데, AE를 학습할 때 여러 layer들을 같이 학습하는 것 보다는 recursion하게 학습하는 것을 생각해보자.
- 즉, Input → layer 1 → layer 2 → laten vector → output layer 1 → output layer 2 → output layer 1 → output이라 하면, 1) input → layer 1 → output으로 학습을 한 후, Layer 1이 새로운 Input이 되어서 2) Layer 1→ layer 2 → laten vector → output layer 1 → output layer 2를 학습하는 것이다.
- 여기서 한번 더 쓰고, output layer의 결과값은 Layer 1의 결과값과 비교하여 Loss를 계산하는 방식이다.
- 이걸 이용하여 일부만 덜어내서 Classification을 할 때 사용할 수 있고, semi-supervised learning을 할 때도 사용이 가능하다.
Variational Auto Encoding
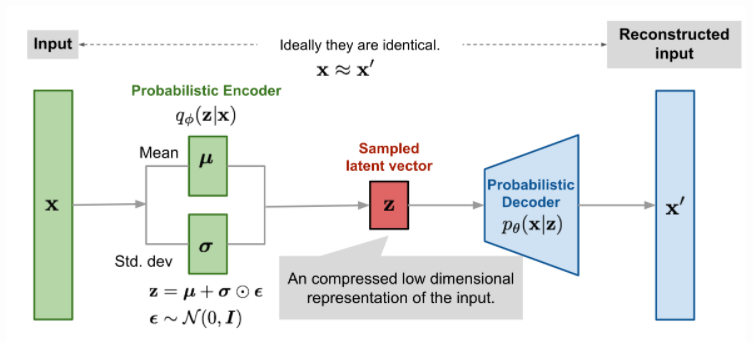
- 앞에서는 laten vector을 만들기 위함에 초점을 두 었다면, 이제는 data를 generating하는 것에 초점을 두자.
- 참고로 VAE는 AE에서 파생된 것이 아니라, 알고보니 AE와 구성이 비슷하여 VAE로 이름이 붙었다.
- 이렇게 이미지를 생성하는 것을 이미지 생성기(Generative Adversial network, GAN)이라 한다.
- 다음 챕터의 내용
- 말했다시피 구성은 굉장히 비슷하고, 이전의 AE에서는 하나의 laten vector를 생성해냈다면 이제는 non-deterministic하게 generating 하기 위해 Mean vector과 Standard derivation vector를 생성해낸다. (무슨 의미냐면, laten vector 여서 random으로 sampling을 하고, 평균과 표준편차를 Input에서 가져오는 것이다)
- 일단 laten vector에서 임의의 에 대해 decoder가 결정하는 것 부터 생각하자.
- 편의를 위해 는 Gasussian distribution에서 뽑고, 우리가 정해야 하는 것은 이다.
- 이는 학습을 통해서 알아낼 수 있다.
- Law of total probability에 의해 가 되는데, 그러면 생각해볼 요소는 “과연 모든 에 대해 이를 계산할 수 있는가?”이다.
- 실제로 이거는 불가능하고, 이를 intractable하다라고 한다.
- Bayes theorem(Bayesian inference)에 의해 인데, 아쉽게도 도 intractable하다.
- 근데, 분모의 의 의미를 다시 생각해보면 가 결정이 되었을 때 의 분포이고, 이는 Encoder의 역할이다.
- 하지만 우리는 Encoder를 정확하게 결정할 수 없으므로, 이를 학습하는 Neural Network 로 approximation하여 Inference한다는 것이 핵심이다. (Variational Inference)
- 편의를 위해 의 분포, encoder의 분포 모두 Gaussian이라 가정을 한다.
- 그러면, 우리가 해야할 일은 1) Reconstruction error를 줄여야 하고 2) 에 따른 의 분포를(Nerual Network) 원래의 분포()와 비슷해지게 backpropagation을 이용하여 잘 정해야 한다.
- 1번은 Reconstruction error, 2번은 Regularzation error라고 한다.
- 하지만 그러면 우리는 2번은 “분포”의 오차를 줄이는 것인데, 이 분포의 오차를 어떻게 줄일 것인가?
- 앞의 7번 Softmax & Loss에서 Deep learning에서 label 각각이 아니라 분포로 보면 KL-Divergence를 줄이는 것이라고 말했다.
- 즉, 분포 간의 차는 KL-Divergence를 Minimization 하는 방향으로 가야한다.
- 1)번의 결과는 이고, 2번은 로 바꿀 수 있다. 이때 결국은 Gaussian으로 간다고 했으므로 으로 나타낼 수 있고, 따라서 총 Error은
로 표현이 가능하고, 이를 이용하여 Backpropagation을 수행해야 한다.
- 하지만, 에서 로 가게 되는데, 에서 가 direct로 정해지는 것이 아니라 분포에서 하나 뽑는 것을 기억하라.
- 즉, 는 Randomness가 있다는 것이고, 이 때문에 Backpropagation이 불가능하게 된다!
- 이를 해결하기 위해 Reparameterization trick이라는 것을 활용해야한다.
Reparameterization trick
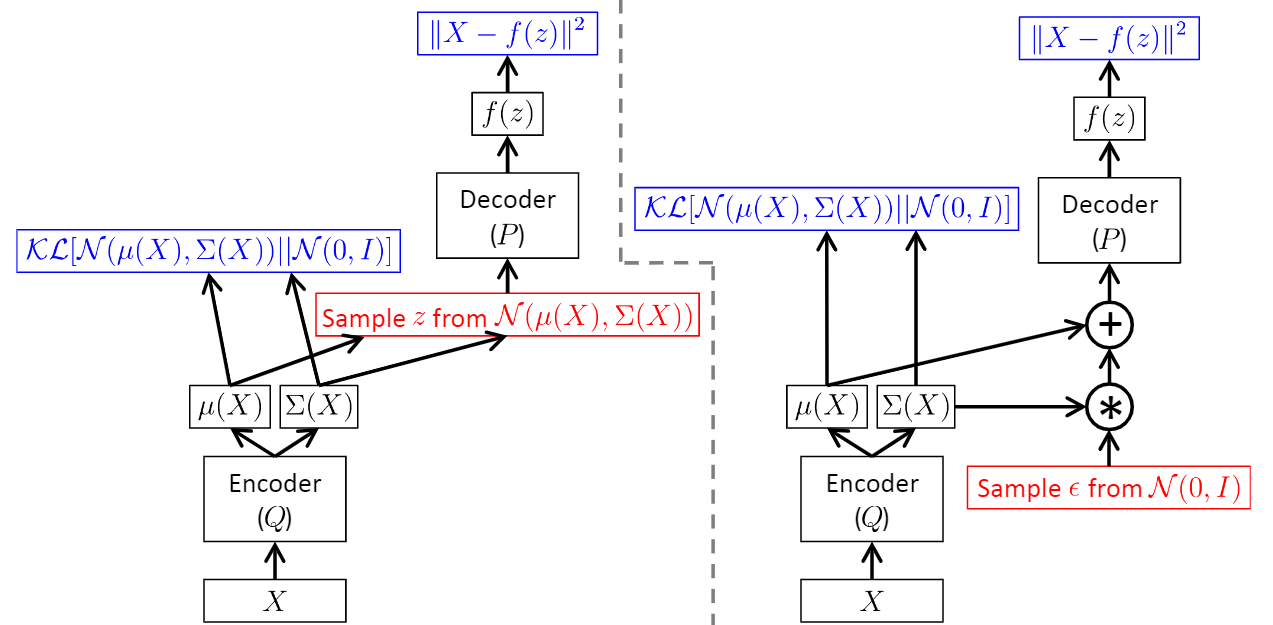
- 원래라면 에서 하나를 뽑는 것이고, 여기서 랜덤성이 존재하여 우리는 역전파를 진행할 수 없었다.
- 하지만 가우시안 같은 경우 정규분포를 만큼 scaling하고 만큼 shift하는 것으로 해석을 할 수 있다.
- 즉, 우리는 에서 뽑은 이후 로 나타낼 수 있다.
- 이때, 와 은 independent하므로 에 대해 미분할 때 은 constant 처리하면 된다!
- 따라서, randomness가 배제되었기 때문에 backpropagation을 정상적으로 진행할 수 있다.
Uploaded by N2T